
LLM WikiとSelf-pedia | メンバー限定記事

最近、LLM Wikiが人気のようです。生成AIに「personal knowledge bases」を作ってもらう、というもの。
こういうフレーズってかっこいいですよね。でも、それが何を指しているのかはあんまりわかりません。実際、”PKM”という言葉も使っている人によって意味の幅がかなり広いので、言葉のお守り的使用に近づいている気がします。
というわけで、LLM Wikiの説明を読んでみると、問題提起は明確です。
生成AIを使って情報を扱うときには、RAG(Retrieval Augmented Generation)のようなものが用いられます。代表的なのが各要素をベクトル化し、検索したいものもベクトル化して、その「距離の近さ」から探すといったもの。これは毎回ググッているだけに等しく、ちょっとイメージして欲しいんですが、毎回ググッて終わりにしているだけの人は賢くはならないわけですよね。情報は常に検索ごとに断片的に表示されるだけ。これじゃいかんだろう、というのが著者の問題提起です。
そこで、wikiを作ろうじゃないか、というのがこのLLM Wikiで、もちろん「LLMについてのwiki」ではなく、「LLMによるwiki」という意味です。すでにこのネーミング自体が混乱を呼ぶわけですが(wikiとは何か、に答えられますか)、それはさておいて、ここでwikiによるアプローチが出てくる点が興味深いですね。
だって、wikiというやり方は、ウォード・カニンガムが1995年ごろから発展させてきた、「知を集める」手法をベースにしており、ようは「人間のための知の技法」なわけです。それがいま、生成AIの「知の技法」として提案されているのは、感慨深いものがありますね。
(この辺の話は『パターン、Wiki、XP ~時を超えた創造の原則 (WEB+DB PRESS plusシリーズ)』が面白いです)
実際、大規模なコーディングの進め方、チームのマネジメント、作業でミスしないための方策など、効果を挙げているものは「それ、人間でもやってましたよね」と言えるものばかりです。生成AI用の特別な何かというよりも、「人間向けの技法を、生成AIにおいて適用する」ことが頻繁に行われている。このことから考えられることは山ほどありますが、ひとまずは置いておきましょう。
たくさんの情報を保存しておき、毎回LLMに「ググら」せて終わりにするのではなく、むしろ新しい情報が入ることで成長して いく「構造」を作ろうではないか、というのがLLM wikiが目指すアプローチです。
Instead of just retrieving from raw documents at query time, the LLM incrementally builds and maintains a persistent wiki — a structured, interlinked collection of markdown files that sits between you and the raw sources. When you add a new source, the LLM doesn’t just index it for later retrieval. It reads it, extracts the key information, and integrates it into the existing wiki —
(クエリ時に生のドキュメントから取得するだけでなく、LLMは永続的なWikiを段階的に構築し、維持します。これは、ユーザーと生のソースの間に存在する、構造化され相互にリンクされたMarkdownファイルのコレクションです。新しいソースを追加すると、LLMは後で取得するためにそれをインデックス化するだけではありません。 LLMは情報を読み込み、重要な情報を抽出し、既存のWikiに統合します)
片方にユーザーがいて、もう片方に生データ(raw data)があるときに、その間に立つものがLLM wikiです。その内部は、「構造化され相互にリンクされたMarkdownファイル」となっています。この”構造化され相互にリンクされた”が、ここで使われているwikiという言葉の含意なのでしょう。
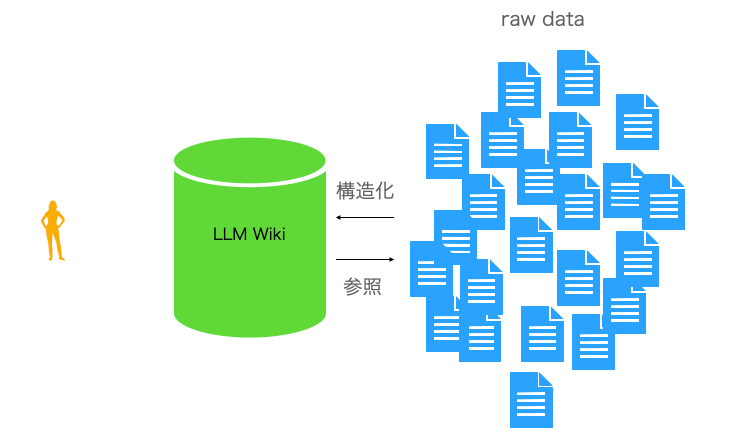
ユーザーが行うのは、せっせと生データ(raw data)を放り込むことだけです。新しい情報が加えられるたびに(ベクトル化もされつつ)、その情報がLLM Wikiに取り込まれます。
たとえば、経済学の本を読んで読書メモを書いたら、おそらく「経済学」のページに新しい項目が追加されるのでしょう(何も確定的なことが言えないのがこの方法のポイントです)。別の日に違う経済学の本を読んでも、何かしら関係あるページに情報が追記・更新される。そんな感じで、日々の情報摂取のエッセンスが、自動的にそのwikiに取り込まれていきます。
You never (or rarely) write the wiki yourself — the LLM writes and maintains all of it. You’re in charge of sourcing, exploration, and asking the right questions. The LLM does all the grunt work — the summarizing, cross-referencing, filing, and bookkeeping that makes a knowledge base actually useful over time.
(あなたがWikiを自分で書くことはほとんどありません(あるいは全くありません)。すべてはLLMが作成し、維持管理します。あなたは情報源の選定、調査、そして適切な質問をする責任を負います。LLMは、知識ベースを長期的に実際に役立つものにするための、要約、相互参照、ファイリング、記録といった面倒な作業をすべて行います)
拙著に『生成AIとライフハック』にこんな一節を書きました。
これまでのノートツールでは、自分でファイルやノートをつくって保存していました。
その際に、後から自分がそれを見つけられるように、ノートブックやタグづけなどのメタ情報を工夫することが必須でした。将来的にはそのような「検索のための工夫」はかなり必要度が低くなるかもしれません。
まさに私が予想した通りの流れがやってきています。実際、「プロジェクト・ソクラテス」という試みでは、私はただ自分の考えを生成AIに投げ掛けるだけで、そのファイル生成はすべて生成AIに任せていました。ただそれだけのことでも、何か取り出したい考えがあるならば生成AIに尋ねればいい、という状況ができあがっていました。そのときは、特定のプロジェクトだけというコンテキストの限定があったのですが、それをより広範囲にすればLLM Wikiに相当するのでしょう。
また、ObsidianのノートのタグづけにGemini APIのサポートを使うことがあるのですが、こういう「機械的」なことは人間がやらなくていい、ないしは人間がやらなくていい、という場合が結構あります。
デジタルノートにおけるメタ情報の付与は、その大半が「後からそれを見つけられるようにする」ための営みで、その営みだけならば生成AIに代替してもらってぜんぜんへっちゃらです。むしろ積極的にそうしてもらった方がいい、とすら言えるかもしれません。
もちろん、その目的が「後からそれを見つけられるようにする」だけであれば、という保留がつきますが。
ライフログのデータ管理
先に、このやり方が役立つ領域を検討しましょう。
