
情報整理4.0、そしてもう一度過去へと

前回は、「人間が行ってきた」情報整理の流れを確認しました。

情報整理3.0にあたる「リンクによる整理」が、デジタル的情報整理の最先端だったといってよいでしょう。もちろん、「2020年頃までは」という保留がつきます。
ChatGPT以降急激にその能力を増してきた生成AI(LLM)は、もう一歩先の情報整理、つまり、情報整理4.0の可能性を見せてくれています。
単に聞く
一番簡単な例から考えてみましょう。7万以上ノートがあるEvernoteにおいて、AIチャットで「仙台に行ったときの情報」を聞いてみました。

私は旅行の記録をほとんど残さないので、Foursquareのチェックイン情報を統合して表示してくれています。
別の例でやってみましょう。
「まどか☆マギカについて書いた文章を探して。」
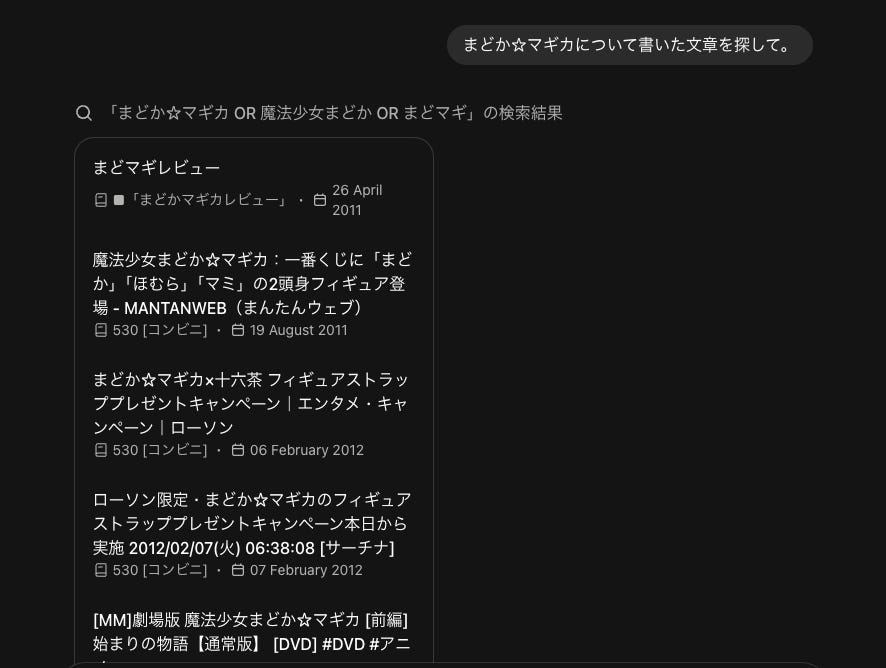
私の指示から、生成AIが包括的なキーワードを設定し、それで検索を実行してくれています。
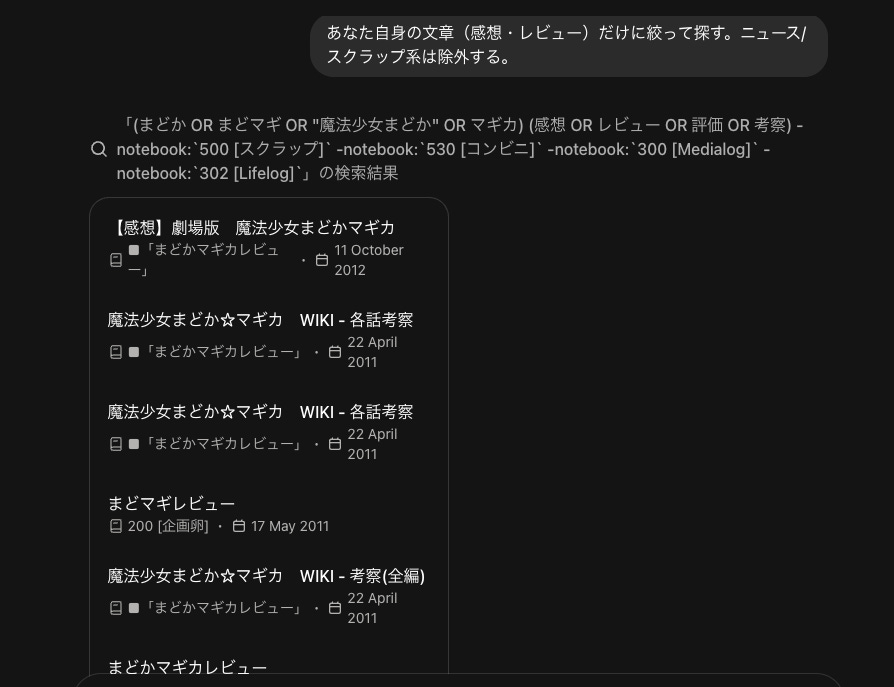
絞り込みをお願いしたら、「それっぽい」ノートブックを省くように検索キーワードを再編しました。
超複雑な検索をやってくれていますが、私が入力しているのは日常的な日本語の指示だけです。
そして、さらに絞り込みます。

ここまでの検索はノートブックなど私が設定した整理軸によるフィルタリングでしたが、ここでは「中身」を確認し、私の期待に沿うようなものが選り分けられています。つまり、この段階ではメタ情報は関係ありません。何を書いたかによって、情報が選別されているのです。
以上は、そこまで高性能とは思えないEvernote AIでの「情報探し」です。それでもここまでのことができてしまいます。あと一年もすれば、もっと高度かつ複雑な情報の探し方を「簡単な日本語」だけでトリガーすることができるようになるでしょう。
見つけること?
さて、私たちが情報を保存し整理するのは、後からそれを見つけて使うためです。保存する情報が増えると、見つけるのが難しくなるので、ノートブック・タグ・リンクなどを使って「見つけるための道筋」を整備してきたのが、これまでの情報整理でした。
しかし、です。
最初の例をもう一度見てみましょう。

ここではいわゆる検索→発見という通常のプロセスは行われていません。言い換えれば、私が保存した情報をそのまま見ているわけではないのです。保存された情報から、必要に合わせて新しい情報が生成されています。
保存→検索→発見
というこれまでのルートではなく、
保存→利用→生成
という別様のルートが生まれています。
まったく新しい情報整理の可能性が感じられるのではないでしょうか。
たとえば、以下は「タスク管理の基本」という雑なプロンプトにEvernote AIが答えてくれたものです。

私がこれまでに書いた原稿をベースに、情報が生成されています。書いたものそのものを見つけ出して利用するのとは、完全に違う「情報整理」の形です。
情報を保存していく
思考実験をしてみましょう。
今この瞬間にまったく新しいプログラミング言語が生まれたとします。名前をHailWorldとでもしておきます。私はその情報を調べながら、知識や書き方のコツを一つひとつノートにしたためていきます。
これまでの情報整理であれば、まず「プログラミング」というノートブックを作り、その中に「HailWorld」というサブノートブックを作って、そこにノートを配置していくことになるでしょう。あるいは、HailWorldはタグになって各種のノートに添付されるかもしれません。モダンにやれば、バックリンクを使う可能性もあります。
生成AIを使えばどうでしょうか。
一つひとつノートにしたためるところまでは同じとして、それをノートブックやタグやリンクを使って整理するのではなく、ただ「HailWorldの繰り返し構文ってどう書きますか」とだけ尋ねる。そうすれば、それまでに保存されたノートを参照しながら、生成AIは、「繰り返し処理はこう書きます」と教えてくれる。
「自分が情報を保存し、後からそれを使っている」という構図そのものは同じでも、整理についてのアプローチがまったく違っています。必要な情報をノートとタイトルにすべて込めておけば、ノートブックといった補助的なメタ情報を使う必要がないのです。
それまでの情報整理なら「HailWorldの繰り返し構文」「HailWorldの変数宣言」「HailWorldの例外処理」といったタイトルは冗長でしょう。それをまとめるために(名前空間を定義するために)ノートブックやフォルダは活躍していました。また、wikiリンクなどでも、そうしたタイトルのつけ方をしてしまうとサジェストがかなり鬱陶しいことになるので、名づけは工夫されていたはずです。
しかしそれは、保存したノートを見つけ出す行為を人間がやることが前提の整理でした。生成AIが「インターフェース」となるならば、まったく違ったアプローチが可能になってきます。
後から見つけ出すための「整理」はほとんど不要になる可能性すら出てきているのです。
揺らぎある個
そもそも人間は、精密な処理の繰り返しはさほど得意ではありません。しかし、メタ情報の付与は、一定の規則に添って行わないと使い物になりません。
以下の記事では、GeminiのAPIを使ってノートにタグ付けをお願いする工夫を紹介していますが、おそらくこうした方向はノートツールに標準化されていくでしょう。
もっと言えば「ノートを書く」という行為すら、人間が行う必要がなくなります。生成AIとやりとりして、その結果を生成AIがノートにする。そして、それらのノートを生成AIが利用して、ユーザーに情報を提示する。
そうしたとき、整理の「理」(ことわり)を担保しているのは、人間ではなく生成AIです。それが意味するのは、人間が「整理のための作業」から解放されることです。
私たちはただ情報と戯れ、それを利用するだけで済むのです。
本当にそれでいいのか?
以上のように生成AIはまったく新しい情報整理の形を顕現させようとしていますが、私がわざわざ過去の情報整理を振り返ってこの話を確認したのは、はたしてこれが単純な「アップデート」だと言えるのかどうか、という疑問があるからです。
というよりも、そうではないだろうという仮説があります。
私たちがこれまでにやってきた「情報整理」は、ただ「情報を後から見つけるため」だけの事務的な作業ではなく、何か別の意義があったのではないか。
だとしたら、「すべて生成AIに任せればいい」とは言えなくなります。もちろん、生成AIを使わなくてもいいという話にもなりません。そうではなく、何をやってもらって、何をやってもらわないのかを判断する話になるはずなのです。
一冊の本に索引をつくるのは相当な部分事務的な作業になりますが、もちろんそれだけで済む話ではありません。どういうキーワードを設定するのかが、すでに高次の情報整理です。そこには意味の選択・創出という間違いなく知的生産と呼ばれる行為が背後に働いています。
生成AIに索引が作れないと言いたいのではありません。索引をつくろとするとき、人の頭は独特の働き方をしており、それが当人に対する知的な貢献をしているのだ、と言いたいのです。当然その貢献は、成果物を受け取る人に対しても影響を与えるでしょう。
つまり、です。
私たちは生成AIを利用することによって、これまでの「情報を見つけ出すため」に必要な作業から解放されることになります。それは──ごく単純な見方をすれば──リソースが解放されるということです。
その解放されたリソースを使って、別の意義を持つ「情報整理」を行うようにするのがよいのではないか。
これが私が考えたい新時代の情報整理であり、つまりは知的生産です。
だとしたら、かつて行われていた情報整理にはどんな知的意義があったのか。それを再確認していく作業が必要になってくるでしょう。